Search engine types
What are Search Engines?
One of the exciting aspects of the Internet is that it allows you to find information that may otherwise be difficult or near impossible to obtain through the use of search engines. There are three main types of search engines, web crawlers, directories, and sponsored links. Search engines typically use a number of methods to collect and retrieve their results. These include:
Crawler databases. The search engine sends out many 'crawlers' which trawl the Web randomly, following links and indexing page content as they go. Some common crawlers are the GoogleBot and MSNBot which power Google and Bing.
Human-edited directories. Directories are human-maintained indexes of websites organized into a comprehensive hierarchy. To add your site to a directory you must submit it to an editor who reviews it first. Many directories charge a fee for inclusion, but the Open Directory Project is a popular free service.
Sponsored links. Sponsored links give you a way to pay to have your site included in search results. When a user searches for one of your chosen keywords, your site will appear usually in a separate section from the main results. On Google these sites appear at the top of the list separated from the main results.
| Search Engine |
Type Of Main Results |
Provider Of Main Results |
Paid Results |
Directory Results |
|---|---|---|---|---|
Crawler |
none |
|||
Crawler |
||||
Crawler |
||||
Crawler |
none |
|||
Crawler |
none |
none |
||
Crawler |
||||
Bing (MSN Search) |
Crawler |
none |
||
Crawler |
||||
Crawler |
none |
|||
Crawler |
Here is an example of crawler and sponsored link results using Yahoo.
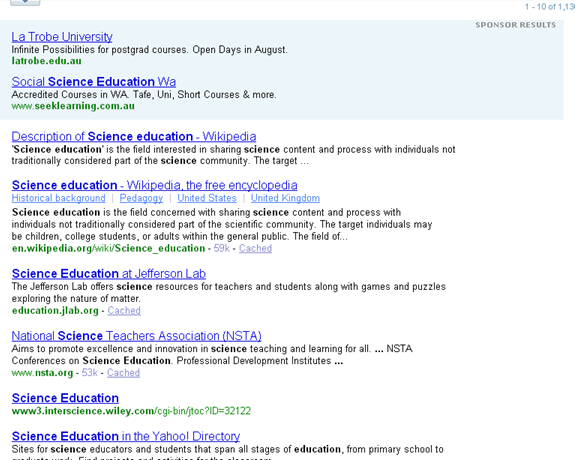
The blue shaded area is sponsored links and the results below this area are crawler based results.
The parts of a Crawler-Based search engine
Crawler-based search engines have three major elements. First is the spider, also called the crawler. The spider visits a web page, reads it, and then follows links to other pages within the site. This is what it means when someone refers to a site being "spidered" or "crawled." The spider returns to the site on a regular basis, such as every month or two, to look for changes.
Everything the spider finds goes into the second part of the search engine, the index. The index, sometimes called the catalog, is like a giant book containing a copy of every web page that the spider finds. If a web page changes, then this book is updated with new information.
Search engine software is the third part of a search engine. This is the program that sifts through the millions of pages recorded in the index to find matches to a search and rank them in order of what it believes is most relevant.
Searching Across Sites
List searches present the user with a list of categories relating to the specific information being researched. By ‘drilling down’ through categories and sub-categories you will eventually get to specific pages that should be relevant to your search. The risk is that if the user gets the wrong category, important information may be missed.
Most list services provide a search box as well so you can still do a text search for your subject but can limit it to the category you are currently looking in. Popular examples of this type of service include Yahoo!, Lycos and LookSmart.
The keyword search gives the user a search box and then uses powerful text search tools to find all pages that contain that information.
The better search engines have very intelligent search methods and Google (one of the most popular) can even detect if you might have spelled a keyword incorrectly in your search string.
Some text search services are adding category searches as well to improve your search capability. Popular examples of this search service are Google and AltaVista.
What are Meta-search engines? How do they work?
Finally the meta-search engines are services that will put your search through a number of more popular search engines. This will hopefully improve your search by finding pages or files that are contained in one search service and not another – Dogpile is an example of this type of service.
In a meta-search engine, you submit keywords in its search box, and it transmits your search simultaneously to several individual search engines and their databases of web pages. Within a few seconds, you get back results from all the search engines queried. Meta-search engines do not own a database of Web pages; they send your search terms to the databases maintained by search engine companies.
Meta-search engines can be less reliable as most of them tend to return results from smaller and/or free search engines and miscellaneous free directories that are often small and highly commercial.
However Dogpile does access the larger search engines and also offers a unique parallel mode for viewing and comparing each search engine’s results. This is useful to see how little/much they overlap.
Alternative Search Tools
HotBot provides easy access to the web's three major crawler-based search engines: Yahoo, Google and Teoma. Unlike a meta search engine, it cannot blend the results from all of these crawlers together. Nevertheless, it's a fast, easy way to get different web search "opinions" in one place. http://www.hotbot.com
Try it yourself!
Use the topic “science education curriculum” using Dogpile at http://www.dogpile.com/ .
Compare the results of your Dogpile results to those of Google or another search engine.
- What are the advantages you can see using Dogpile instead of one of the other search engines?
- What are the disadvantages of only using Dogpile?
- Look at HotBot and see how your search results vary.
Becoming familiar with several search engines will help you quickly find the information you are looking for by using the best search tool.